Finally built a text classifier - Part 1
A text classifier primarily uses machine learning principles to classify text into different categories.
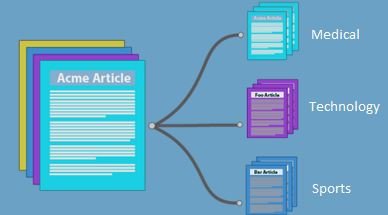
These supervised learning based classifiers are used in a variety of different places such as spam filters, user comment categorization, etc.
Text categorization is the grouping of documents into a fixed number of predefined classes. Each document can be in multiple, exactly one, or no category at all. Using machine learning, the objective is to classifiers from examples which perform the category tasks automatically. This is a supervised learning problem. Since categories may overlap, each category is treated as a separate group.
Supervised Learning for Text Classification.
PART-I : Training
1) During training, a feature extractor is used to transform each input value to a feature set.
2) These feature sets, which capture the basic information about each input that should be used to categorize it.
3) Pairs of feature sets and labels are fed into the machine learning algorithm to produce a model.
PART-II : Prediction
1) During prediction, the same feature extractor is used to transform unobserved inputs to feature sets. These feature sets are then fed into the model, which produces predicted labels.
Implementation of Text Classification using Naive Bayes Classifier.
What is the Naive Bayes Classifier?
The Naive Bayes classifier is a simple probabilistic classifier which is based on Bayes theorem with strong and naive independence assumptions. It is one of the most basic text classification techniques with various applications in email spam detection, document categorization, language detection, sentiment detection and automatic medical diagnosis. It is one of the most basic text classification techniques used in various applications. It is highly scalable.
The process flow for the Text Classification.
A. Preparing the dataset
Step 1: Reading the Data from the dataset.
Step 2: Divide the dataset into two parts as training dataset and testing dataset.
Step 3: Create a corpus for training dataset and testing dataset.
Step 4: Performing the Data processing transformation on the training dataset and testing datasets.
B. Cleaning up text and applying the model
1. Transform characters to lower case.
2. Converting to Plain Text Document.
3. Remove punctuation marks.
4. Remove digits from the documents.
5. Remove from the document's words which we find redundant for text mining (e.g.
Pronouns, conjunctions). We set this words as stop words(“English”) which is a built-in list for the English language.
6. Remove extra whitespaces from the documents.
Step 5: Now create the “Term document matrix”. It describes the frequency of each term in each document in the corpus and performs the transposition of it.
Step 6: Train Naïve Bayes model using transposed “Term document matrix” data and
Target class vector.
Step 7: Apply the prediction on the generated model for the testing dataset.

Comments
Post a Comment