Part - Of - Speech Tagging
One of the more powerful aspects of the NLTK module is the Part of Speech tagging that it can do for you. This means labelling words in a sentence as nouns, adjectives, verbs...etc. Even more impressive, it also labels by tense, and more. Parts of speech (POS) are specific lexical categories to which words are assigned based on their syntactic context and role. The main POS are noun, verb, adjective, and adverb. The process of classifying and labelling POS tags for words called parts of speech tagging or POS tagging. POS tags are used to annotate words and depict their POS, which is really helpful when we need to use the same annotated text later in NLP-based applications because we can filter by specific parts of speech and utilize that information to perform specific analysis, such as narrowing down upon nouns and seeing which ones are the most prominent, word sense disambiguation, and grammar analysis.
Github link for POS tagging example:
https://github.com/jayeetaroy/Text-analytics-Python/blob/master/POS%20tagging.ipynb
From the following image, we can compare the results of POS tagging in the script.

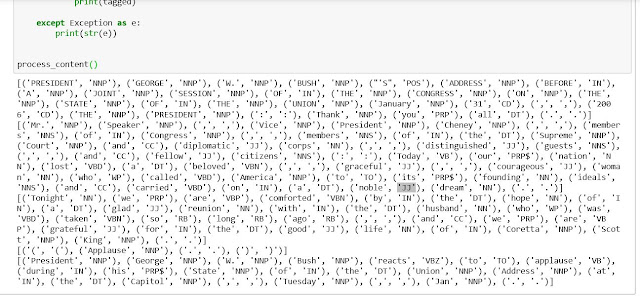
As we can observe, for the word 'president', the POS tagger classified it as NNP- Proper noun singular. Similarly, the entire paragraph has been broken down into words and their POS has been identified.
Chunking
Now that we know the parts of speech, the next step is called chunking, where words are grouped into hopefully meaningful chunks. One of the main goals of chunking is to group into what are known as "noun phrases." These are phrases of one or more words that contain a noun, maybe some descriptive words, maybe a verb, and maybe something like an adverb. The idea is to group nouns with the words that are in relation to them.
Github link for POS tagging example:
https://github.com/jayeetaroy/Text-analytics-Python/blob/master/POS%20tagging.ipynb
From the following image, we can compare the results of POS tagging in the script.

As we can observe, for the word 'president', the POS tagger classified it as NNP- Proper noun singular. Similarly, the entire paragraph has been broken down into words and their POS has been identified.
Chunking
Now that we know the parts of speech, the next step is called chunking, where words are grouped into hopefully meaningful chunks. One of the main goals of chunking is to group into what are known as "noun phrases." These are phrases of one or more words that contain a noun, maybe some descriptive words, maybe a verb, and maybe something like an adverb. The idea is to group nouns with the words that are in relation to them.

Comments
Post a Comment